What happens after typing the words?
When we started this project, people would often say something like, “So, you have to get a computer to recognize the words on the page. That’s basically it, right? What else is there to do?”
Lots more!
One very important task has been marking up the words using XML (eXtensible Markup Language). XML works a lot like html, for those of you familiar with html, but instead of relying on a limited set of tags, XML lets us invent new tags to fit our project. Additionally, where html normally addresses the appearance of a text, XML lets us mark the kind of content that the text represents. Our project mainly uses a variety of XML called TEI, named for the Text Encoding Initiative, a consortium that developed and maintained it.
Our project owes an enormous debt of gratitude to Ian Lancashire of the Lexicons of Early Modern English (LEME) project at the University of Toronto, who donated to us a complete TEI-encoded transcription of Johnson’s 1755 first folio edition.
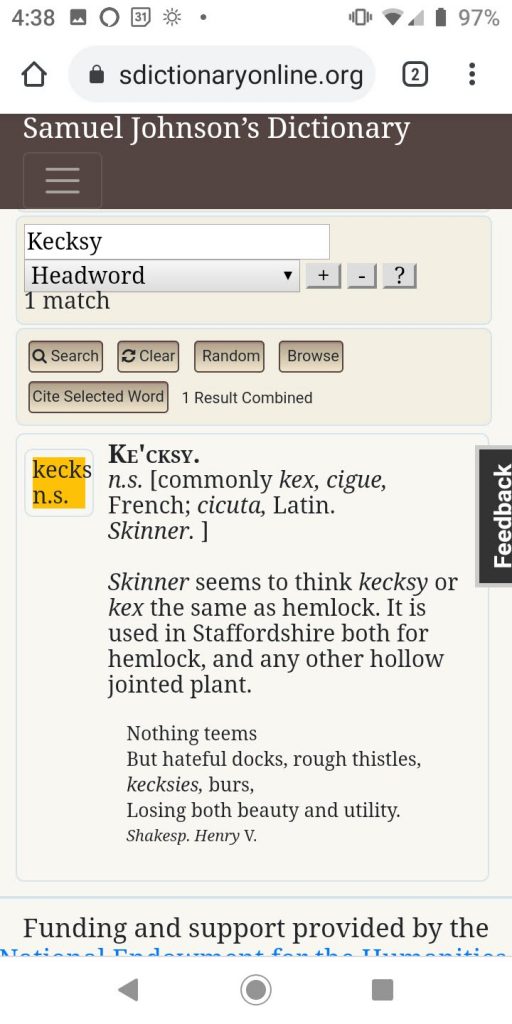
Without that gift, we might still be cleaning up text that was generated via OCR (Optical Character Recognition). OCR technology does not yet do a good job of recognizing 18th century print. For example, here’s an example of the OCR output for kecksy, followed by a facsimile image of the entry for kecksy:


Predictably, the software has trouble recognizing the long “s” character. But when it fails to understand ʃ, it doesn’t simply insert an f. It substitutes f, or j; in other passages it might substitute t or l or p or 1 or a wide variety of other characters, or it might just skip the letter altogether. And the software also had trouble with E, c, n, s, e, and h . . . and that’s just in this relatively short entry!
You can see how the transcript from LEME has made our work much easier!
Still, even though the LEME file was already marked in XML-TEI, we still had plenty of markup to do. Here’s a portion of the entry for kecksy as marked in the original LEME transcription and then as marked in our edited transcription:


The LEME markup faithfully preserves the layout on the printed page, which is an important goal of digital humanities.
However, our dictionary prioritizes accessibility over preservation. Readers can view the original printed pages using our “Browse” menu, and soon we will display a facsimile of every entry alongside every transcription. Because our readers can easily view the original print layout, our transcription doesn’t need to preserve every detail of that layout. Instead, our goal is to provide transcribed text that can be easily read, quoted, etc. To reach this goal, we removed some markup, such as </lb> tags that marked line breaks. Our transcribed text flows to match whatever margins are set by the reader’s device.

Additionally, we added markup to enable our database to work more effectively. For example, we marked “Skinner” as the name of an author, with a link to our personography table that will soon allow readers to display additional information about him. And we added attributes to language names to enable our database to locate mentions of a language no matter how it is abbreviated. For example, our database can find mentions of French whether it is spelled French or Fr., and it can distinguish between the French language and other things that are French.
We were able to use a software process for some of this markup, but much of it we completed by hand: teams of people, combing through the dictionary one entry at a time, looking for features to mark. To make the process easier, we built an administrative display that indicated the presence of some tags with colored font. That way, when we saw a word in blue (for example), we could tell that it was already marked with a <placeName> tag without having to open up the XML file.

Of course, if the name of a place did not appear in blue, we did need to open up the XML file for that word to add the tag. Happily, eXide, the database that stores our XML files, provides a web-based interface for easier editing. Our volunteers have spent many hours of quality time editing the XML.
Would we consider this work to be drudgery? Sometimes! But Johnson’s definitions are a delight, so the work can be surprisingly engaging.
As the project moves forward, we will provide additional search features that have been made possible through this labor.